
Что такое LSI и LSA
В эпоху Баден-Бадена, Фреда, Королева и нашествия ИИ, когда речь идет о копирайтинге или seo, мы стали часто слышать сочетание слов: «LSI-копирайтинг», «LSI тексты», «латентно-семантический анализ», «скрытое семантическое индексирование». Многие «сеошники» действительно узнали обо всем этом только сейчас, хотя метод LSA (Latent semantic analysis) был разработан в далеком 1980, и запатентован в 1988 году.
Вот что по этому поводу гласит Википедия:
Латентно-семантический анализ (ЛСА) (англ. Latent semantic analysis, LSA) — это метод обработки информации на естественном языке, анализирующий взаимосвязь между коллекцией документов и терминами в них встречающимися, сопоставляющий некоторые факторы (тематики) всем документам и терминам.
В основе метода латентно-семантического анализа лежат принципы факторного анализа, в частности, выявление латентных связей изучаемых явлений или объектов. При классификации / кластеризации документов этот метод используется для извлечения контекстно-зависимых значений лексических единиц при помощи статистической обработки больших корпусов текстов.
Статьи Вики не всегда комфортны для восприятия, поэтому попробуем разобраться в том, что такое LSI простыми словами, и по возможности постичь этот дзен SEO-копирайтинга.
Особенности копирайтинга по LSI
Изначально метод LSA использовали для того, чтобы машина могла понять неоднозначный текст, различать синонимы и омонимы, и тем самым получать некие данные о принадлежности текста той или иной сфере и тематики. Анализ производился по матричной схеме, используя математику. Пример терм-документной матрицы мы рассмотрим ниже.
LSI текст категорически не может быть рерайтом с одного источника. Чтобы текст ранжировался ПС необходимо, чтобы он нес больше полезности, чем конкуренты, застрявшие в ТОПе уже сейчас, сочетал и приумножал информацию, которую они дают.
Таким образом, LSI-копирайтинг представляет собой способ написания текстов, который позволяет увеличить релевантность контента, индексируемых поисковыми машинами, за счет использования большого количества синонимов и связанных с темой текста слов. Метод, в первую очередь, направлен на то, чтобы сделать контент максимально полезными пользователям, но SEO-специалисты, конечно же, стараются использовать его на благо покорения ТОПа поисковых систем. 🙂
Пример слов с LSI
Допустим, пользователь вводит в поисковой строке слово «машина». Задача поисковой машины определить, о какой именно машине идет речь по сопутствующим словам. Если это в тексте есть «запчасти», «продать», «ремонт», то скорее всего речь идет об автомобиле. Если это слова «бытовая», «стирка» и прочее, то его отправят на страницы со стиральными машинами. Вот эти дополнительные слова как раз являются одной из составляющих LSI ядра.
Использование LSI ядра помогает машине лучше понять потребности пользователя и предложить наиболее соответствующие запросу сайты. С внедрением в алгоритмы поисковиков методов машинного обучения и искусственного интеллекта все стало немного сложнее. Но приятнее для юзера. Теперь на первых строчках выдачи Яндекса и Google все чаще можно встретить приятные сайты и информативные статьи, не заспамленные ключевыми словами. Метод «слон купить москва» уже давно ушел в небытие, а теперь и «купить слона в москве, приобрести слона недорого и со скидкой» станет менее актуальной проблемой.
Для справедливости стоит отметить, что принцип работы LSI менее заметен в коммерческих текстах. Скорее всего он поможет странице интернет-магазина стать ближе к заветной десятке ТОПа, но не будет столь же значительным, что и для информационной статьи.
Такие принципы поисковой выдачи сделали возможным появление LSI-копирайтеров, работа которых в корне отличается от безликой штамповки «качественных и продающих SEO текстов».
SEO-контент VS LSI
Топорный сео-копирайтинг был широко распространен многие годы: тексты со странными несогласованными словосочетаниями, порой заспамленные повторами и неуместными упоминаниями. Справедливости ради замечу, что сейчас он встречается все реже, и ключи чаще вписаны в текст обдумано и незаметно, так сказать «поестественнее». Именно такие тексты являются предпосылками LSI.
Основные отличия и преимущества текстов, написанных по результату скрытого семантического анализа, от обычного SEO-копирайтинга заключаются в следующем:
- LSI-статьи обычно намного объемнее SEO-текстов, оыбчно, это минимум 5000 знаков без пробелов, чаще ключи в них имеют полное вхождение многословных низкочастотных фраз, и дополняются так же и синонимичными и задающими тематику словами. Для написания LSI текста, кроме набора ключей из вашего семантического ядра понадобится еще и собрать дополнительное LSI ядро.
- LSI-статьи зачастую могут не содержать стандартных ключевых фраз из СЯ сайта вообще, или ни разу не использовать ключевики в точном вхождении.
- Такие тексты призваны быть полезными, давать актуальную информацию и раскрывать тему, а не просто презентовать товары и услуги. Они понятны, удобочитаемы, именно поэтому высоко ценятся и людьми и поисковыми системами.
Кто-то скажет, что LSI помогает только с НЧ (низкочастотными) запросами. Это в большой степени действительно так, но представьте, какое количество НЧ и уникальных запросов может получить ваш сайт! Посетители из органического поиска «горячие», они уже хотят приобрести ваш товар или услугу, остается только правильно приподнести.
Те же люди, что жалуются по поводу низкой частотности LSI ядра, часто выдвигают версии, что стандартные SEO-тексты помогут «вырастить» позиции ВЧ (высокочастотных) запросов. А это уже в корне неверно. Ваши ВЧ скорее подтянутся, ввиду улучшения поведенческих факторов на страницы, ввиду постоянного притока посетителей по низкочастотным запросам.
Преимущества LSI-копирайтинга
Есть несколько неоспоримых плюсов, говорящих в пользу латентно-семантического индекса:
- ассоциативные фразы, слова синонимы увеличивают информативность и читабельность текста и вызывают доверие поисковых систем, а если текст написан грамотно и с точки зрения психологии покупателя — посетителей сайта тоже;
- открываемость текстов увеличивается, так как пользователи находят в них интересующую информацию (если ваш LSI копирайтер не халтурщик));
- если контент грамотно структурирован, и написан легко, увеличивается время пребывания пользователей на сайте;
- вы достаточно быстро заметите значительное повышение позиций в ранжировании, в основном по низкочастотным запросам в поисковых системах, не только за счет LSI ядра, но и ввиду уменьшения заспамленности;
- для сайта произойдет естественное наращивание ссылочной массы, так как сторонний ресурсы с большим удовольствием используют ссылки на качественный контент подобной тематики.
Недостатки LSI-копирайтинга
Ну и без минусов не обходится, конечно же:
метод не учитывает порядок слов в предложениях, поэтому даже бессвязный текст может быть расценен как релевантный (радует, что обычно не на долго);
все возможные значения слов на самом деле не раскрыты;
живой язык, с использованием иронии и сарказма (как, например, в этой статье) не воспринимается поисковым роботом, поэтому нужно тщательно следить за используемыми словами, и при этом не «утяжелять» текст, оставлять его комфортным для прочтения;
при анализе текста, поисковая система может сделать акцент только на значимых ключевых словах, в то время как другие запросы окажутся без внимания.
И конечно же, главным недостатком LSI-текстов является их цена. Чтобы написать качественный текст необходимо изучить много информации и затратить намного больше времени, чем на обычный seo-текст, ведь объем такой статьи, мягко говоря, большой, и при этом она должна быть информативной. Просто подлить водички, ради количества знаков, не выйдет. Стоит такой труд не дешево.
Как собрать LSI ядро
Так как это объемная и важная тема, она заслуживает совершенно отдельного рассмотрения. Поэтому я просто дам вам полезную ссылку на статью Деваки (кто не знает — это Сергей Кокшаров, известный и классный SEO-аналитик). У него есть достаточно много статей, посвященных LSI, но именно тут: https://devaka.ru/articles/Lsi-tools собран отличный инструментарий.
Это не реклама, все инструменты протестированы большим количеством SEO-специалистов и копирайтеров. У меня есть, что сказать по этому поводу в дополнение, и я обязательно скажу, но позже. 😎
Терм-документная матрица
Как и обещалось — возвращаемся к этому вопросу. Терм-документная матрица — это исходная точка LSA (скрытого семантического анализа, если забыли).
Элементы этой матрицы содержат веса терминов в документах, назначенные с помощью выбранной весовой функции. В качестве примера можно рассмотреть самый простой вариант такой матрицы, в которой вес термина равен 1, если он встретился в документе (независимо от количества появлений),и 0 если не встретился.
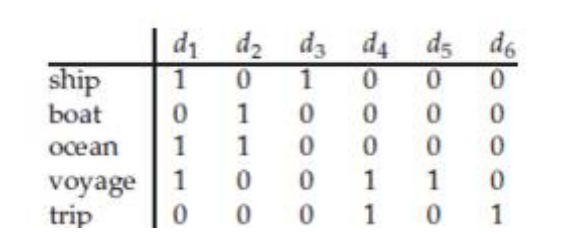
d1-d6 — это документы, в первом столбце — слова, то есть, термины
Видим, что некоторые термины встречаются вместе в одном документе а другие — нет. Поисковые системы обладают базой текстов, и коллекциями слов, которые в полной мере отражают особенности естественного языка. Это позволяет создавать огромные терм-документные матрицы и на их основе делать достоверные выводы о взаимосвязях между словами и принадлежности текстов к той или иной тематике.
Однако огромный размер хорош только в плане статистической достоверности. Напрямую работать с матрицей, которая получена из миллиардов текстов, невозможно, так как требует слишком больших машинных ресурсов.
И тут вступает в бой сингулярное разложение — математическая операция, которая позволяет сделать терм-документную матрицу проще, выделить из нее только самое важное. Это и есть «проекция в пространство более низкой размерности, которое содержит семантические концепции исходного набора документов».
Если вас интересуют детали матчасти, рекомендую статью habrahabr. Там на простом примере отлично отражены этапы разложения.
Что нужно знать LSI копирайтеру
«Так как писать-то? Конретнее можно про ваш LSI ?» — скажете вы, и будете правы.
Чтобы получить качественный LSI-текст к составлению ТЗ тоже нужно подойти со всей ответственностью, просто составить список ключевиков мало, нужно дополнительное LSI ядро.
Не всякий копирайтер справится с такой работой. Хороший LSI-копирайтер должен:
- уметь быстро и глубоко погрузится в тему, включить экспертный анализ;
- писать большие тексты, которые сочетают и приумножают информацию из многих источников, при этом, без лишней воды;
- подбирать LSI-слова, даже если их нет в ТЗ;
- писать легко читаемые и полезные тексты для людей, а не для поисковых систем.
Принципы написания текста с использованием LSI
Цифры
- для больших текстов более 5000 знаков, на каждые 1000 слов должно приходится около 100 LSI-слов;
- в текстах до 3000 знаков количество LSI-слов не должно превышать 30;
- в Title необходимо применять как минимум 5 слов из LSI-ядра, без потери заголовком естественности;
- оптимально использовать хотя бы одно LSI-слово в каждом предложении.
Структура
- информация должна излагаться последовательно, логически, быть написана на экспертном уровне, но простым понятным языком, с использованием, но без злоупотребления специальными терминами (здесь, конечно, многое зависит от аудитории, на которую текст направлен);
- ·не стоит слишком увлекаться лирикой и нарушать семантическую связь, использовать много словесного мусора;
- разноуровневые заголовки, буллиты, перечисления и выноски помогут сделать текст читаемым;
- картинки, фото, графики, схемы и видеролики — несомненный плюс;
- ссылайтесь на экспертные мнения, привлекайте статистику, данные исследований, комментарии специалистов (исходящие ссылки на доверенные и качественные ресурсы давно перестали быть отрицательным фактором ранжирования; главное, чтобы ссылка была к месту и полезна).
Как и где использовать ключи
Ключевые фразы и слова в LSI-текстах располагаются равномерно и должны присутствовать во всех его частях, а не только в теле статьи:
- в заголовках title и h1-h6;
- в метатегах;
- в введении и заключении;
- в тегах и хэштегах;
- в ссылочных анкорах.
Уникальность, заспамленность и водность статьи — по-прежнему важные параметры. Проверяйте их.
LSI-копирайтинг, в сочетании с честным и правильным SEO, корректной технической оптимизацией, позволит улучшить позиции сайта в поисковых системах (актуально и для Яндекса, и для Google, и для остальных). Как следствие, увеличить трафик, привлечь аудиторию, мотивировать посетителя на целевое действие и повысить уровень доверия поисковиков и людей, увеличивая конверсию.